Character Boundaries
BreakIterator
that locates character boundaries, you invoke the
getCharacterInstance method, as follows:
BreakIterator characterIterator =
BreakIterator.getCharacterInstance(currentLocale);
This type of BreakIterator
detects boundaries between user characters, not just Unicode characters.
A user character may be composed of more than one Unicode character. For example, the user character ü can be composed by combining the Unicode characters \u0075 (u) and \u00a8 (¨). This isn't the best example, however, because the character ü may also be represented by the single Unicode character \u00fc. We'll draw on the Arabic language for a more realistic example.
In Arabic the word for house is:
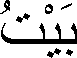
This word contains three user characters, but it is composed of the following six Unicode characters:
String house = "\u0628" + "\u064e" + "\u064a" + "\u0652" + "\u067a" + "\u064f";
The Unicode characters at positions 1, 3, and 5 in the house
string are diacritics. Arabic requires diacritics because they can
alter the meanings of words. The diacritics in the example are
nonspacing characters, since they appear above the base characters. In
an Arabic word processor you cannot move the cursor on the screen once
for every Unicode character in the string. Instead you must move it
once for every user character, which may be composed by more than one
Unicode character. Therefore you must use a BreakIterator
to scan the user characters in the string.
The sample program
BreakIteratorDemo,
creates a BreakIterator
to scan Arabic characters. The program passes this BreakIterator,
along with the String object created previously, to a
method named listPositions:
BreakIterator arCharIterator =
BreakIterator.getCharacterInstance(new Locale ("ar","SA"));
listPositions (house, arCharIterator);
The listPositions
method uses a BreakIterator
to locate the character boundaries in the string. Note that the
BreakIteratorDemo assigns a particular string to the
BreakIterator with the setText
method. The program retrieves the first character boundary with the
first method and then invokes the next
method until the constant BreakIterator.DONE
is returned. The code for this routine is as follows:
static void listPositions(String target, BreakIterator iterator) {
iterator.setText(target);
int boundary = iterator.first();
while (boundary != BreakIterator.DONE) {
System.out.println (boundary);
boundary = iterator.next();
}
}
The listPositions method prints out the following boundary
positions for the user characters in the string house.
Note that the positions of the diacritics (1, 3, 5) are not listed:
0 2 4 6
